

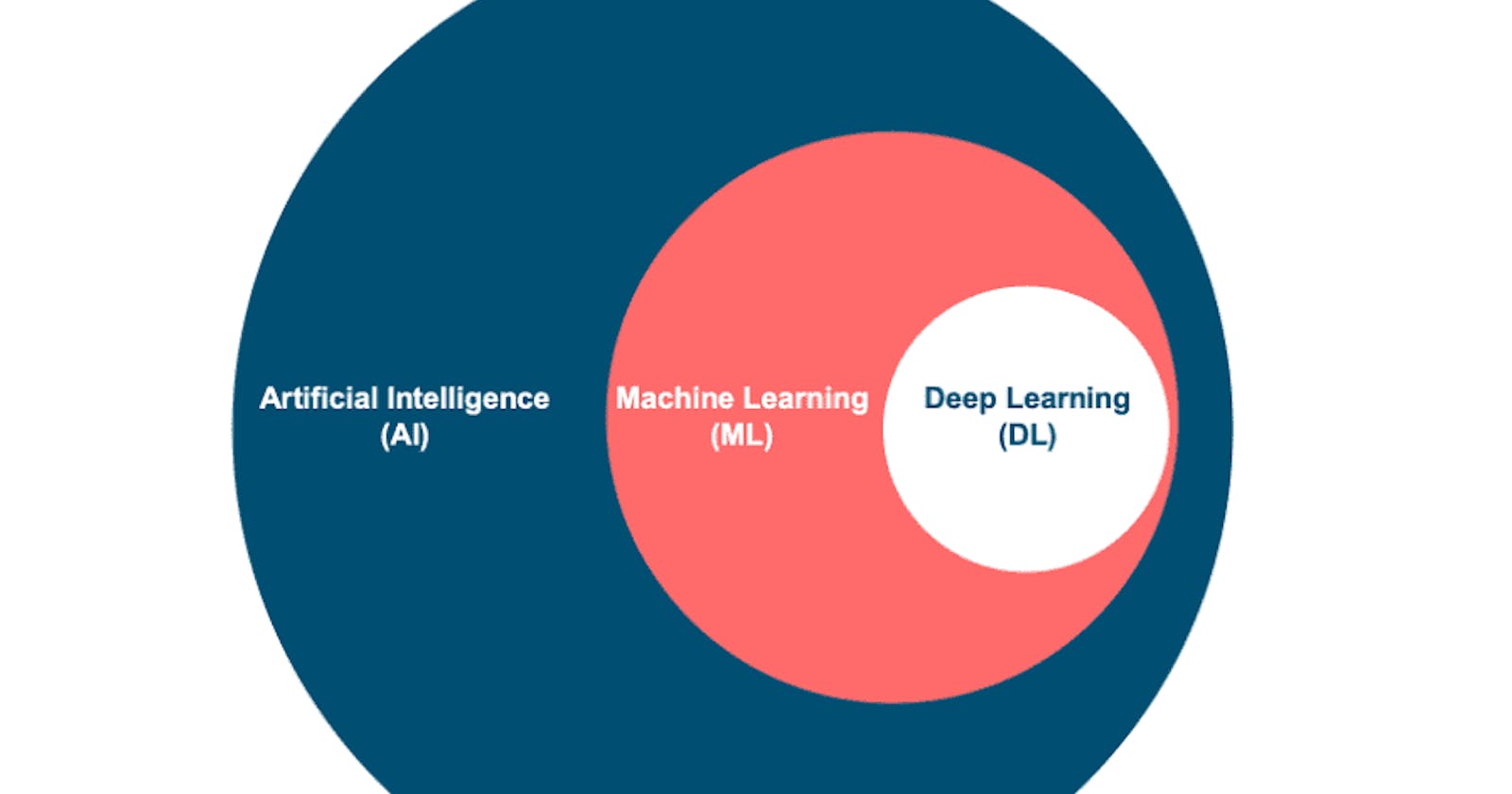
AI vs ML vs DL:
Artificial Intelligence (AI):
- Definition: AI simulates human intelligence to perform tasks and make decisions.
Machine Learning (ML):
- Definition: ML is a subset of AI that uses algorithms to learn patterns from data.
Deep Learning (DL):
- Definition: DL is a subset of ML that employs artificial neural networks for complex tasks.
Definition of Machine Learning (ML):
- ML enables computers to learn from data and previous experiences without being explicitly programmed.
Types of Machine Learning (ML):
Supervised Learning:
Definition: In supervised learning, machines are trained using labeled datasets, where inputs are mapped to corresponding outputs.
Example: Identifying objects in images based on features like shape, size, and color.
Categories:
a) Classification: Predicting categorical outputs like spam vs. non-spam emails.
b) Regression: Predicting continuous outputs such as stock prices.
Advantages:
Effective for classification and regression tasks.
Requires less computational power compared to other types.
Disadvantages:
Relies heavily on labeled data.
May overfit if not enough diverse data is available.
Unsupervised Learning:
- Definition: In unsupervised learning, machines are trained using unlabeled datasets, finding patterns and categories without supervision.
Example: Clustering similar data points together based on their similarities.
Categories: Clustering, Association, Dimensionality Reduction.
Advantages:
Useful for clustering and anomaly detection.
Doesn't require labeled data, making it versatile.
Disadvantages:
Harder to evaluate results due to lack of ground truth labels.
Can be computationally intensive for large datasets.
Semi-supervised Learning:
Definition: Semi-supervised learning uses a mix of labeled and unlabeled data during training, offering a middle ground between supervised and unsupervised learning.
Example: Classifying images with a combination of labeled and unlabeled data.
Advantages:
Combines benefits of both supervised and unsupervised learning.
Useful for scenarios with limited labeled data.
Disadvantages:
Requires careful selection of labeled and unlabeled data.
Performance may be affected if the balance between labeled and unlabeled data is not maintained.
Reinforcement Learning:
Definition: Reinforcement learning operates on a feedback-based process, where agents learn by trial and error, receiving rewards for desirable actions.
Example: Teaching a computer program to play chess or navigate a maze.
Advantages:
Ideal for sequential decision-making tasks.
Learns through trial and error, mimicking human learning.
Disadvantages:
Prone to high variance and instability during training.
Requires extensive computational resources and time for training.
Summary:
Supervised learning relies on labeled data for predicting outputs, while unsupervised learning finds patterns in unlabeled data.
Semi-supervised learning combines labeled and unlabeled data for training, offering efficiency and flexibility.
Reinforcement learning learns through interaction with the environment, receiving rewards for desirable actions.